
Table of Contents
Kubernetesの2ノードクラスタにRookをデプロイして、小さいCephクラスタを作ってCephFSのボリュームを切り出してみた。
Rook
RookはKubernetes上に分散ストレージシステムをデプロイして管理するOSSのオペレータ。
サポートしているストレージプロバイダは現在のv1.4時点でCeph、EdgeFS、Cassandra、CockroachDB、NFS、YugabyteDBだけど、StableなのはCephとEdgeFSだけで他はAlpha。 さらに、EdgeFSがOSSじゃなくなってRookがサポート落としかけたこともあってRook/EdgeFSは先行き怪しいので、今のところRookは実質ほぼCeph専用と言っていいかもしれない。
Ceph
Cephは様々なインターフェースでアクセスできる分散オブジェクトストレージプラットフォーム。 Red Hatが商用版を展開しているけど、OSSなので無料でも使える。
CephのコアはRADOSという分散オブジェクトストア。 RADOSは、OSDとMONによるクラスタ(Ceph Storage Cluster)として構成される。
OSDはディスク単位で動いてそのディスクへのI/Oを司るデーモン。 RADOSで管理するディスクの数だけ動く。
MONはOSDの監視、クラスタの構成情報(Cluster Map)の管理、CLIクライアントに対するインターフェースの役割をするデーモン。 普通は高可用性のために複数動き、Paxosで合意形成する。
Cephにはもう一つ新しめなコンポーネントとして、Ceph Manager (MGR)というデーモンがある。 これはMONと同じ数だけ同じノードで動いて、Ceph Storage Clusterの監視や管理のためのインターフェースとかCeph Dashboardを提供してくれるもの。 Ceph v11ではオプショナルだったけど、Ceph v12からほぼ必須のデーモンになった。
MGRの機能はモジュラー構成になっていて、以下のようなモジュールがビルトインされている。
- Dashboard module: Ceph Dashboard。
- RESTful module: クラスタステータスを取得するREST API。
- Zabbix module: Zabbixにクラスタステータスを定期的にpushしてくれるモジュール。
- Prometheus module: Prometheusからクラスタステータスを取れるようにするためのexporter。
- Telemetry module: クラスタの情報をCeph開発者コミュニティに送るモジュール。
- Crash module: Cephのデーモンのクラッシュダンプを集めてクラスタに保存してくれるモジュール。
- Rook module: CephとKubernetesを連携させるモジュール。
Cephのストレージインターフェース
RADOSにアクセスしてデータ読み書きする手段はいくつかあって、一番プリミティブなのがlibradosというライブラリを使ってAPIを呼ぶものなんだけど、RADOSの上に実装されたストレージインターフェースもあって、そっち経由でアクセスするのが多分普通。
ストレージインターフェースには以下の3つがある:
-
POSIX互換のファイルシステム。mount.cephでマウントできるほか、NFSとしてexportしてマウントすることもできる。
-
ブロックデバイス。シンプロビジョニングでリサイザブル。RBDとも呼ばれる。 というかRBDと呼ばれることの方が多い。 デバイスファイルにマッピングしたり、QEMU/KVMのVMやKubernetesのPodからマウントしたり、iSCSIでつないだりできる。
-
オブジェクトストレージ。AWSのS3やOpenStackのSwiftと互換性がある。RADOSGWとも呼ばれる。
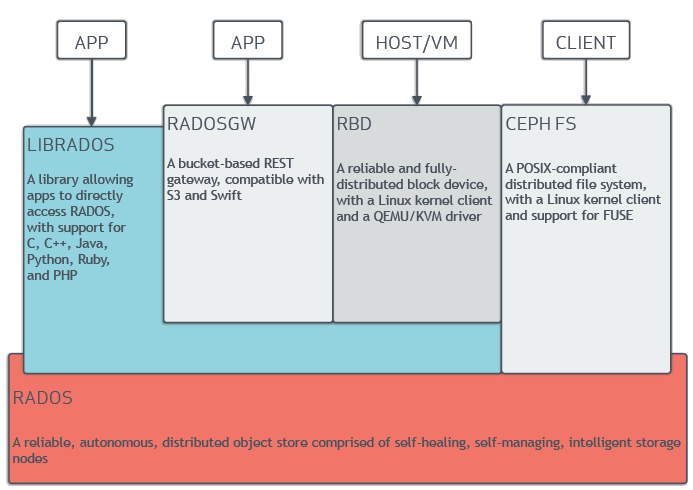
KubernetesのPodにマウントするストレージとしてはCephFSかRBDが使えるけど、CephFSのボリュームは複数のノードのPodでマウントできるのに対し、RBDのは単一のNodeでしかマウントできないので、CephFSのほうがユースケース広そう。
なので今回はCephFSを試す。
CephFS
CephFSはPOSIX互換のファイルシステムで、スケーラブルで高性能。 性能を確保するために、ファイルの実態のI/Oを担当するOSDとは別に、ファイルのメタデータを扱うMDS (Metadata Server)というデーモンが動くアーキテクチャになっている。

Pool
PoolはCephのCeph Storage Clusterを論理的に分割するもの。 Poolごとにデータの冗長性などの設定やCluster Mapが分けられる。
Poolは少なくともストレージインターフェース毎に分かれる。 CephFSはファイルシステムのメタデータ用とファイルの実データ用の二つのPoolを使う。
OSDのストレージバックエンド
割と余談なんだけど、OSDがRADOSのオブジェクトを永続化するためのバックエンドには、FileStoreとBlueStoreの二種類がある。
FileStoreはXFSやBtrfsといったPOSIX互換のファイルシステムに依存するもの。 BlueStoreはFileStoreより新しいやつで、ストレージデバイスに直接アクセスするので、ファイルシステムのオーバーヘッドが無い分FileStoreより性能がいい。
Rookは現在最新のv1.4の時点でBlueStoreだけをサポートしている。
Rook/CephでCephFSのPVを作ってPostgreSQLポッドで使う
以降、実際にRookを触っていく。
参考資料:
- Rookのマニュアル
- Rookのサンプルマニフェスト
- Cephの手動デプロイ手順
環境
VMware PlayerのVMを二つ使って、Oracle Linux 7.4をいれて2ノードのKubernetesクラスタを作って、そこにRookをデプロイする。
VMはともにCPUコア一つメモリ4GBの貧弱なスペック。
ホスト名はk8s-masterとk8s-node。
それぞれにOSD用の10GBの未フォーマットのディスクを追加した。
追加したディスクのデバイスファイルはともに/dev/sdb
Kubernetesのバージョンは1.19.2。 Rookのバージョンは1.4.5。 Cephのバージョンは15.2.4。
OSD用のPVをデプロイ
OSD用のストレージデバイスとしては、生のディスク全体、ディスクのパーティション、LVMの論理ボリューム(など?)が使えるんだけど、今回は生のディスク全体を使ってみる。
RookでOSDに使わせるストレージデバイスはCephClusterというRookのカスタムリソースに指定する。 指定する形式にHost-basedとPVC-basedと二種類ある。 前者はノードのホスト名やデバイスファイル名をCephClusterに直接書く形式で、後者はRaw Block VolumeのPVにバインドするPVC(のテンプレート)をCephClusterに書く形式。 PVC-basedの方が新しいし、物理的なリソースとKubernetesのリソースとの分離がよりはっきりしていいので、そちらを使うことにする。
Raw Block VolumeのPVは動的プロビジョニングできたらかっこいいけど、今回は簡単に前もって手動で作っておくことにする。
k8s-masterとk8s-nodeの分、合わせて二つとして以下をapplyした。
---
kind: PersistentVolume
apiVersion: v1
metadata:
name: k8s-master-sdb
labels:
osd: "true"
spec:
volumeMode: Block
capacity:
storage: 10Gi
local:
path: /dev/sdb
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s-master
---
kind: PersistentVolume
apiVersion: v1
metadata:
name: k8s-node-sdb
labels:
osd: "true"
spec:
volumeMode: Block
capacity:
storage: 10Gi
local:
path: /dev/sdb
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s-nodeラベルのosd: "true"は、OSDのPVCとバインドするときにラベルセレクタで使う目印。
volumeModeがBlockで、pathにデバイスファイルを指定しているのがRaw Block VolumeのPVならでは。
ボリュームプラグインがlocalなのでnodeAffinityでホスト名を使ってノード名を指定している。
Rookの共通リソースをデプロイ
ここからRookをデプロイしていく。 まずは共通リソース。
RookのGitリポジトリにあるcommon.yamlをapplyすればいい。
[root]# git clone https://github.com/rook/rook.git
[root]# cd rook/cluster/examples/kubernetes/ceph
[root]# git co v1.4.5
[root]# kubectl apply -f common.yamlこれでRookのNamespaceとかCustomResourceDefinitionとかRoleとかが作られる。
Rook/Cephオペレータをデプロイ
Rook/Cephオペレータのマニフェストはcommon.yamlと同じディレクトリのoperator.yaml。 そのままだとRBDとCephFS両方のCSIドライバが有効になってるけど、CephFSしか使わないのでRBDを無効にする。
--- a/cluster/examples/kubernetes/ceph/operator.yaml
+++ b/cluster/examples/kubernetes/ceph/operator.yaml
@@ -27,7 +27,7 @@ data:
# To run the non-default version of the CSI driver, see the override-able image properties in operator.yaml
ROOK_CSI_ENABLE_CEPHFS: "true"
# Enable the default version of the CSI RBD driver. To start another version of the CSI driver, see image properties below.
- ROOK_CSI_ENABLE_RBD: "true"
+ ROOK_CSI_ENABLE_RBD: "false"
ROOK_CSI_ENABLE_GRPC_METRICS: "true"
# Set logging level for csi containers.
また、OSDのデバイスをHost-basedで指定するときにしか使わないデーモンも有効になってるので無効化する。
--- a/cluster/examples/kubernetes/ceph/operator.yaml
+++ b/cluster/examples/kubernetes/ceph/operator.yaml
@@ -399,7 +399,7 @@ spec:
# Whether to start the discovery daemon to watch for raw storage devices on nodes in the cluster.
# This daemon does not need to run if you are only going to create your OSDs based on StorageClassDeviceSets with PVCs.
- name: ROOK_ENABLE_DISCOVERY_DAEMON
- value: "true"
+ value: "false"
# Time to wait until the node controller will move Rook pods to other
# nodes after detecting an unreachable node.
また、嵌りどころだったんだけど、ホストのカーネルバージョンが古いとCephFSを使うPodが以下のようなエラーで立ち上がらない問題が発生する。
Warning FailedMount 4m42s (x12 over 29m) kubelet, k8s-master (combined from similar events): MountVolume.MountDevice failed for volume "pvc-991cbae4-311f-4c8a-bfa9-6af99dde2575" : rpc error: code = Internal desc = an error (exit status 32) occurred while running mount args: [-t ceph 10.0.170.252:6789:/volumes/csi/csi-vol-68a7996a-de9e-11ea-8dcc-e2634a1533d6/ad3ed71f-e4a3-4a2a-9f41-ed3f274a4b54 /var/lib/kubelet/plugins/kubernetes.io/csi/pv/pvc-991cbae4-311f-4c8a-bfa9-6af99dde2575/globalmount -o name=csi-cephfs-node,secretfile=/tmp/csi/keys/keyfile-909027452,mds_namespace=shared-fs,_netdev]これはmount.cephのmds_namespaceオプションが使えないためで、カーネルバージョンが4.10未満だと踏むエラー。 (4.7未満説もある。)
Rook/Cephオペレータの設定を以下のように変えて、CephFSボリュームをカーネルドライバでマウントする代わりにceph-fuseでマウントするようにすればこの問題を回避できる。
--- a/cluster/examples/kubernetes/ceph/operator.yaml
+++ b/cluster/examples/kubernetes/ceph/operator.yaml
@@ -38,7 +38,7 @@ data:
# If you disable the kernel client, your application may be disrupted during upgrade.
# See the upgrade guide: https://rook.io/docs/rook/master/ceph-upgrade.html
# NOTE! cephfs quota is not supported in kernel version < 4.17
- CSI_FORCE_CEPHFS_KERNEL_CLIENT: "true"
+ CSI_FORCE_CEPHFS_KERNEL_CLIENT: "false"
# (Optional) Allow starting unsupported ceph-csi image
ROOK_CSI_ALLOW_UNSUPPORTED_VERSION: "false"
ここまで編集したらapply。
[root]# kubectl apply -f operator.yamlrook-cephというNamespaceでRook/Cephオペレータが動き出す。
[root]# kubectl get po -n rook-ceph
NAME READY STATUS RESTARTS AGE
rook-ceph-operator-7c6fb4bf5f-8zn54 1/1 Running 1 4d3hCeph Storage Clusterをデプロイ
次はCephClusterをapplyしてCeph Storage Cluster(i.e. OSDとMONとMGR)をデプロイするんだけど、その前にCephの各デーモンのカスタム設定を作っておく。
これは、rook-config-overrideという名前のConfigMapを作ってCephの設定を書いておくと、Rookが作る設定を上書きできるというもの。
作らなくても動くけど、今回作るCeph Storage ClusterはOSDの数が2つで推奨構成の3つ以上より少ないので、それについてだけ設定しておく。
カスタム設定として以下のyamlファイルをapplyした。
kind: ConfigMap
apiVersion: v1
metadata:
name: rook-config-override
namespace: rook-ceph
data:
config: |
[global]
osd pool default size = 2で、CephCluster。 PVC-basedなCephClusterのマニフェストサンプルはcommon.yamlと同じディレクトリのcluster-on-pvc.yaml。 CephClusterの内容で気にしたところは以下。
データディレクトリ
CephClusterの
spec.dataDirHostPathにはデフォルトで/var/lib/rookが設定されていて、Kubernetesクラスタの各ノードのそのパスにはRookのログとかCephの設定ファイルとかが入る。これは今回そのままにしておく。
MONの設定
MONの数
spec.mon.countにMONを動かすPod数を書く。デフォルトでは3。MONはPaxosで合意形成をするために奇数個である必要がある。今回はKubernetesノードが二つしかないので、1にしておく。
MONのデータストア
spec.mon.volumeClaimTemplateにMONがモニタリングのためのデータを格納するPVをマウントするためのPVC(のテンプレート)を書く。今回は何も指定しないことにする。 指定しないと、
spec.dataDirHostPathに指定したパスの下にデータが入る。
OSDの設定
PVC-basedの設定
PVC-basedの場合、
spec.storage.storageClassDeviceSetsにOSDの設定を書く。spec.storage.storageClassDeviceSets.countがOSDを動かすPod数なので、2にしておく。spec.storage.storageClassDeviceSets.volumeClaimTemplatesにさっきデプロイしたOSD用のPVをマウントするためのPVC(のテンプレート)を書く。 今回はosd: "true"というラベルをキーにしてPVとPVCをバインドさせる。
cluster-on-pvc.yamlの差分は以下。
--- a/cluster/examples/kubernetes/ceph/cluster-on-pvc.yaml
+++ b/cluster/examples/kubernetes/ceph/cluster-on-pvc.yaml
@@ -17,20 +17,8 @@ metadata:
spec:
dataDirHostPath: /var/lib/rook
mon:
- count: 3
+ count: 1
allowMultiplePerNode: false
- # A volume claim template can be specified in which case new monitors (and
- # monitors created during fail over) will construct a PVC based on the
- # template for the monitor's primary storage. Changes to the template do not
- # affect existing monitors. Log data is stored on the HostPath under
- # dataDirHostPath. If no storage requirement is specified, a default storage
- # size appropriate for monitor data will be used.
- volumeClaimTemplate:
- spec:
- storageClassName: gp2
- resources:
- requests:
- storage: 10Gi
cephVersion:
image: ceph/ceph:v15.2.4
allowUnsupported: false
@@ -49,7 +37,7 @@ spec:
storageClassDeviceSets:
- name: set1
# The number of OSDs to create from this device set
- count: 3
+ count: 2
# IMPORTANT: If volumes specified by the storageClassName are not portable across nodes
# this needs to be set to false. For example, if using the local storage provisioner
# this should be false.
@@ -116,11 +104,12 @@ spec:
volumeClaimTemplates:
- metadata:
name: data
# if you are looking at giving your OSD a different CRUSH device class than the one detected by Ceph
# annotations:
# crushDeviceClass: hybrid
spec:
+ selector:
+ matchLabels:
+ osd: 'true'
resources:
requests:
storage: 10Gi
- # IMPORTANT: Change the storage class depending on your environment (e.g. local-storage, gp2)
- storageClassName: gp2
volumeMode: Block
accessModes:
- ReadWriteOnce
ここまで編集したらapply。
[root]# kubectl apply -f cluster-on-pvc.yamlRook/Cephオペレータと同じくrook-cephというNamespaceで、OSD、MON、MGRが動き出す。
OSDのストレージデバイスを初期化するJobとかも実行される。
[root]# kubectl get po -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-provisioner-7478b9dccf-6gnlp 6/6 Running 0 9m43s
csi-cephfsplugin-provisioner-7478b9dccf-w2f6q 6/6 Running 6 8m58s
csi-cephfsplugin-qdsl2 3/3 Running 0 8m18s
csi-cephfsplugin-jl2qj 3/3 Running 0 7m51s
rook-ceph-mgr-a-77cf85dc48-rhr4q 1/1 Running 0 6m36s
rook-ceph-mon-a-7bc4d4d86b-jjbfc 1/1 Running 0 18s
rook-ceph-operator-7c6fb4bf5f-8zn54 1/1 Running 1 4d21h
rook-ceph-osd-0-74bb499d8-dnktb 1/1 Running 0 3m34s
rook-ceph-osd-1-844dccbc49-cvj7t 1/1 Running 1 4m9s
rook-ceph-osd-prepare-set1-data-0-fzhq5-vjbs6 0/1 Completed 0 4d23hCephのデーモン以外にも動いているPodがいる。
csi-cephfspluginはCephFSのボリュームをPVとして扱えるようにするCSIプラグインで、DaemonSetで全Kubernetesノード上でひとつずつ動く。
csi-cephfsplugin-provisionerはCephFSのPVを動的プロビジョニングとかをしてくれるやつで、replicasが2のDeploymentで起動されている。 このreplicasの値など、csi-cephfsplugin-provisionerのDeploymentマニフェストはカスタマイズできないっぽい。
MONのPodであるrook-ceph-mon-a-7bc4d4d86b-jjbfcをkubectl describeしてみると、HostPathで/var/lib/rook/mon-a/dataをマウントしているのが分かる。
また、Node-Selectorsでkubernetes.io/hostname=k8s-nodeが設定されているので、常にk8s-nodeの方のノードで動くようになっている。
MONのデータストアにPVを使うようにした場合はNode-Selectorsは付かないんだろうか。
今回の構成の場合、MONは一つで、常にk8s-node上で動くので、k8s-nodeが落ちるとCeph Storage Clusterが機能しなくなる。
真面目にやるときはMONを3つ以上にして複数ノードに分散させる必要がある。
CephFSをデプロイ
CephFSをあらわすカスタムリソースはCephFilesystemで、そのマニフェストサンプルはcommon.yamlと同じディレクトリのfilesystem.yaml。
CephFilesystemには、MDSの設定と、二つのPoolの設定を書く。 サンプルから変えたのは、各Poolのデータのレプリカ数をOSDの数に合わせたところだけ。
--- a/cluster/examples/kubernetes/ceph/filesystem.yaml
+++ b/cluster/examples/kubernetes/ceph/filesystem.yaml
@@ -13,7 +13,7 @@ spec:
# The metadata pool spec. Must use replication.
metadataPool:
replicated:
- size: 3
+ size: 2
requireSafeReplicaSize: true
parameters:
# Inline compression mode for the data pool
@@ -26,7 +26,7 @@ spec:
dataPools:
- failureDomain: host
replicated:
- size: 3
+ size: 2
# Disallow setting pool with replica 1, this could lead to data loss without recovery.
# Make sure you're *ABSOLUTELY CERTAIN* that is what you want
requireSafeReplicaSize: true
ここまで編集したらapply。
[root]# kubectl apply -f filesystem.yamlRook/Cephオペレータと同じくrook-cephというNamespaceでMDSが動き出す。
MDSはActiveとStandyの二つのPodで動く。
[root]# kubectl get po -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-provisioner-7478b9dccf-6gnlp 6/6 Running 16 8h
csi-cephfsplugin-provisioner-7478b9dccf-w2f6q 6/6 Running 9 8h
csi-cephfsplugin-qdsl2 3/3 Running 0 8h
csi-cephfsplugin-jl2qj 3/3 Running 0 8h
rook-ceph-mds-myfs-a-9cdd75c7d-qhpj9 1/1 Running 4 3d18h
rook-ceph-mds-myfs-b-74fdc8f896-mdnps 1/1 Running 2 3d18h
rook-ceph-mgr-a-77cf85dc48-rhr4q 1/1 Running 2 8h
rook-ceph-mon-a-7bc4d4d86b-jjbfc 1/1 Running 0 8h
rook-ceph-operator-7c6fb4bf5f-8zn54 1/1 Running 1 5d6h
rook-ceph-osd-0-74bb499d8-dnktb 1/1 Running 0 8h
rook-ceph-osd-1-844dccbc49-cvj7t 1/1 Running 1 8h
rook-ceph-osd-prepare-set1-data-0-fzhq5-vjbs6 0/1 Completed 0 5d8hCephダッシュボードを確認
ここで、MGRの機能であるCephダッシュボードにアクセスして、Ceph Storage Clusterの状態を確認してみる。
Cephダッシュボードはrook-cephのNamespaceにあるrook-ceph-mgr-dashboardというServiceでKubernetesクラスタ内に公開されている。
これにクラスタ外からアクセスするにはいくつか方法があるけど、簡単なのはKubernetesノード上でkubectl port-forwardを使ってrook-ceph-mgr-dashboardのポートを外部にフォワーディングする方法。
以下のコマンドを実行すると、https://<ノードのIPアドレス>:8443でCephダッシュボードにアクセスできるようになる。
[root]# kubectl port-forward -n rook-ceph --address 0.0.0.0 svc/rook-ceph-mgr-dashboard 8443:8443Cephダッシュボードにアクセスするとログイン画面が出る。

Usernameはadminで、Passwordは以下のコマンドで取得できる文字列を入れるとログインできる。
[root]# kubectl get -n rook-ceph secret rook-ceph-dashboard-password -o jsonpath='{.data.password}'| base64 -d && echoログインすると以下のような画面になる。 MON、OSD、MGR、MDSがちゃんと動いていそうなことが見てとれる。

サイドバーのPoolsを開くと、CephFSのPoolであるmyfs-data0 (実データ用)とmyfs-metadata (メタデータ用)のPoolができていることが分かる。
Pool名のプレフィックスのmyfsは前節で作ったCephFilesystemのリソース名。

CephFSのStorageClassを登録
CephFSのPVは、CephFSを要求するPVCを作るとcsi-cephfsplugin-provisionerが作ってくれる。
CephFSを要求するPVCには、プロビジョナにrook-ceph.cephfs.csi.ceph.comを指定したStorageClassを使う必要があるので、まずそのStorageClassを作る。
CephFSのStorageClassのマニフェストサンプルは、RookのGitリポジトリのルートからみてrook/cluster/examples/kubernetes/ceph/csi/cephfs/storageclass.yaml。
このファイルの中身は以下のようになっている。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-cephfs
provisioner: rook-ceph.cephfs.csi.ceph.com
parameters:
# clusterID is the namespace where operator is deployed.
clusterID: rook-ceph
# CephFS filesystem name into which the volume shall be created
fsName: myfs
# Ceph pool into which the volume shall be created
# Required for provisionVolume: "true"
pool: myfs-data0
# Root path of an existing CephFS volume
# Required for provisionVolume: "false"
# rootPath: /absolute/path
# The secrets contain Ceph admin credentials. These are generated automatically by the operator
# in the same namespace as the cluster.
csi.storage.k8s.io/provisioner-secret-name: rook-csi-cephfs-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph
csi.storage.k8s.io/controller-expand-secret-name: rook-csi-cephfs-provisioner
csi.storage.k8s.io/controller-expand-secret-namespace: rook-ceph
csi.storage.k8s.io/node-stage-secret-name: rook-csi-cephfs-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph
# (optional) The driver can use either ceph-fuse (fuse) or ceph kernel client (kernel)
# If omitted, default volume mounter will be used - this is determined by probing for ceph-fuse
# or by setting the default mounter explicitly via --volumemounter command-line argument.
# mounter: kernel
reclaimPolicy: Delete
allowVolumeExpansion: true
mountOptions:
# uncomment the following line for debugging
#- debugコメントをみてちょっと編集すれば使えるようになっている。
特に気にすべきところはparameters.fsNameとparameters.pool。それぞれ、CephFilesystemのリソース名と実データ用Pool名。
あとはreclaimPolicyくらいを見ておけばいいか。
今回はこのままでapplyすればいい。
[root]# kubectl apply -f csi/cephfs/storageclass.yamlこれでrook-cephfsという名前のStorageClassが登録できた。
CephFSのPVを作成
前節で登録したStorageClassを指定したPVCを作ると、自動でCephFSのPVが作られることを確認する。 以下のPVCをapplyする。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: cephfs-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
storageClassName: rook-cephfsPVをgetしてみる。
[root]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
k8s-master-sdb 10Gi RWO Retain Bound rook-ceph/set1-data-0-fzhq5 6d8h
k8s-node-sdb 10Gi RWO Retain Bound rook-ceph/set1-data-1-f6bm6 6d8h
pvc-c041509d-96da-4975-b3fc-51e0e66983a1 1Gi RWX Delete Bound default/cephfs-pvc rook-cephfs 4d17hpvc-c041509d-96da-4975-b3fc-51e0e66983a1という名前のCephFSのPVが作られてた。
CephFSのPVをPostgreSQLのPodでマウントする
前節で作られたCephFSのPVを実際にマウントして使ってみる。
PostgreSQLのPodを一つ作るため、以下のマニフェストを使う。
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: psp:priv
rules:
- apiGroups:
- policy
resourceNames:
- privileged
resources:
- podsecuritypolicies
verbs:
- use
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: default:psp:privileged
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: psp:priv
subjects:
- kind: ServiceAccount
name: default
namespace: default
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgresql-deployment
spec:
selector:
matchLabels:
app: postgresql
replicas: 1
template:
metadata:
labels:
app: postgresql
spec:
containers:
- name: postgres
image: postgres:11.9
ports:
- containerPort: 5432
env:
- name: POSTGRES_PASSWORD
value: admin
- name: PGDATA
value: /var/lib/postgresql/data/pgdata
volumeMounts:
- name: cephfs-pvc
mountPath: /var/lib/postgresql/data
volumes:
- name: cephfs-pvc
persistentVolumeClaim:
claimName: cephfs-pvcRoleとRoleBindingはPodSecurityPolicyが有効な環境でのおまじない。
その下にDeploymentがあって、postgres:11.9のコンテナイメージを起動して、前節で作ったcephfs-pvcをマウントしてデータ領域(PGDATA)として使うようにしている。
これをapplyするとPostgreSQLポッドが起動する。
[root]# kubectl get po
NAME READY STATUS RESTARTS AGE
postgresql-deployment-68ff869bcb-8jtn4 1/1 Running 2 3d6hちゃんと動いてるか見るため、Pod内にexecでbashを起動して簡単なSQLを叩いてみる。
[root]# kubectl exec -it postgresql-deployment-68ff869bcb-8jtn4 -- bash
root@postgresql-deployment-68ff869bcb-8jtn4:/# psql -U postgres postgres
psql (11.9 (Debian 11.9-1.pgdg90+1))
Type "help" for help.
postgres=# create table test (id integer, name varchar(10));
CREATE TABLE
postgres=# insert into test values (1, 'hogehoge');
INSERT 0 1
postgres=# select * from test;
id | name
----+----------
1 | hogehoge
(1 row)
postgres=#動いているっぽい。
今回はここまで。