ズンドコキヨシ with LangGraph/LangChain - ズンドコキヨシするLLMマルチエージェントをつくった
Tue, Aug 20, 2024
GenAI Groq OpenAI GPT LangChain LangGraph zundoko
Table of Contents
氷川きよしの芸能活動復帰を記念して、LangGraphとLangChainでズンドコキヨシするLLMマルチエージェントを作った話し。
Javaの講義、試験が「自作関数を作り記述しなさい」って問題だったから
— てくも (@kumiromilk) 2016年3月9日
「ズン」「ドコ」のいずれかをランダムで出力し続けて「ズン」「ズン」「ズン」「ズン」「ドコ」の配列が出たら「キ・ヨ・シ!」って出力した後終了って関数作ったら満点で単位貰ってた
LangGraphとは
LangGraphはLLMエージェントを開発するためのライブラリで、LangChainとシームレスに統合できる。
以前の記事で使ったLangChainのAgentsという機能でもLLMエージェントを作れるけど、Agentsは現時点で非推奨になっていて、LangGraphへの移行が推奨されている。 LangGraphのほうがより柔軟に処理を書ける。
LangChainではDAG状の、つまり有限の一方向の処理しか書けないのに対して、LangGraphでは循環グラフ状の処理を書けるのが大きな特徴。 ReActみたいな、考えて、ツールで情報収集して、それをもとにまた考えて、みたいな、サイクリックなLLMエージェントを柔軟に書ける。
LangGraphのエージェントでもAgentsと同様に、LangChainのToolやToolkitを利用できるんだけど、今回はそれらビルトインのツールの代わりにカスタムツールを作って使ってみる。
LangGraphの仕組み
LangGraphでは、StateとNodeを定義して、Node間をEdgeでつなぐことで、エージェントの処理フローを表すグラフを定義する。 Edgeは、Stateの内容を見たり見なかったりして、次にどのNodeを実行するか(activeにするか)を決定する。
StateはTypedDictかPydanticのモデルのオブジェクトで、基本はグラフにつき一つ定義する。
NodeはStateを受け取って、Stateを更新するパッチを返す関数(もしくはその処理をするRunnable)。 Nodeが返すのはStateと同じ型のオブジェクトだけど、更新対象の属性にだけ値をいれたもので、グラフのStateはデフォルトではその属性で上書きされる。 Stateの属性ごとにReducerを設定しておくこともできて、設定された場合は、Nodeが返した属性はReducerで処理された後でStateにマージされる。
LangGraphのグラフはLangChainのRunnableを実装していて、invokeするとSTART Nodeから実行を開始し、End Nodeに達すると処理終了し、最終的なStateを返す。
エージェントの実行結果は、この最終的なStateから取り出せる。
Zundokoエージェント
ここから実際に、ズンドコキヨシを実行するZundokoエージェントを作っていく。 今回実装するグラフは以下の形。
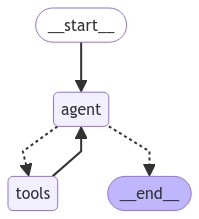
NodeはSTART NodeとEnd Nodeのほかはagentとtoolsだけ。
点線がStateによって条件分岐するEdgeで、実線が無条件のEdge。
処理はagentから始まり、以下のように流れる。
agentではLLMでズンドコキヨシのやり方を解釈し、ズンかドコを生成するためにtoolsに遷移する。toolsでは、カスタムツールでLLMを呼んでズンかドコを生成し、agentに遷移する。agentではキヨシ判定をして、判定できたら「キ・ヨ・シ!」を出力してEnd Nodeに遷移して終わる。判定できなかったら再度toolsに遷移する。
ステップ#1のLLMにはOpenAIの安くて速いモデルのGPT-4o miniを使う。
ステップ#2のカスタムツールでは、何度もLLMを呼ぶので、現時点で無料でAPIが使えるGroqのモデルであるMeta Llama 3 8Bを使う。
複数のLLMを強調させるので、一応マルチエージェントと言えよう。
使う主なPythonモジュールは以下。
- LangChain 0.2.14
- LangGraph 0.2.4
- openai 1.40.8
- langchain-openai 0.1.21
- langchain-groq 0.1.9
これらは以下のコマンドでインストールできる。
$ pip install langchain langgraph openai langchain-openai langchain-groqちなみにPythonのバージョンは3.12.3。
完成したコードはGitHubに置いた。
Zundokoアウトプットパーサ
今回、ズンとドコはGroqのLLMで生成するんだけど、事前に試しにGroqのGUIから生成させてみたら以下のようになった。
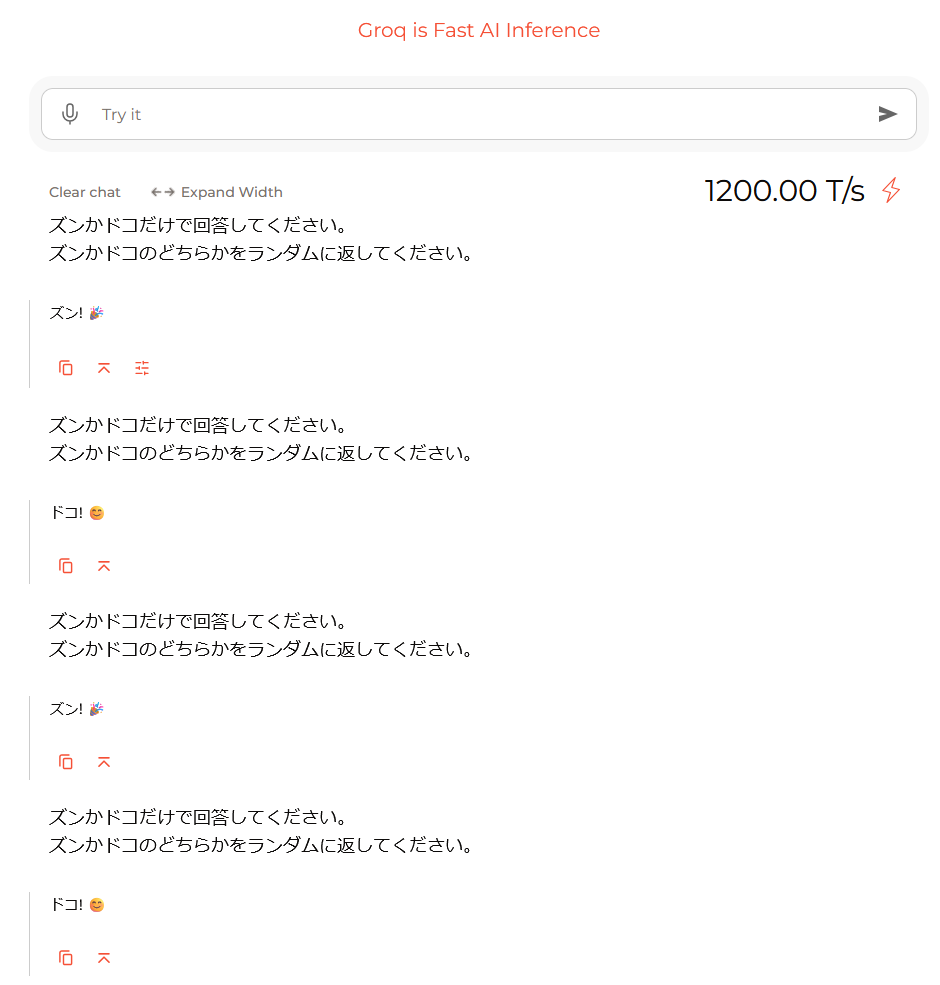
プロンプトで「ズンかドコだけで回答してください」と指示しても、妙にテンションが高いようで、「!」や絵文字を含めて回答してくるので、そこから「ズン」か「ドコ」だけを抽出しないといけない。 そのためにまず、LLMの出力を変換するカスタムアウトプットパーサとして、Zundokoアウトプットパーサを作る。
カスタムアウトプットパーサの一番簡単な実装は、以下のように、LLMの出力を表すAIMessageを受け取り、パースした結果を返す関数を定義するだけ。
app/output_parsers/zundoko_parser.py:
from langchain_core.exceptions import OutputParserException
from langchain_core.messages import AIMessage
def parse_zundoko(ai_message: AIMessage) -> str:
content = ai_message.content
if isinstance(content, str):
if content.find("ズン") >= 0:
print("ズン")
return "ズン"
if content.find("ドコ") >= 0:
print("ドコ")
return "ドコ"
raise OutputParserException(f"Can't parse AIMessage with non-zundoko content: {ai_message}")
else:
raise OutputParserException(f"Can't parse AIMessage with content the type of which is not str: {ai_message}")AIMessageのcontent属性にLLMの回答内容がstring(など)で入ってくるので、そこから「ズン」か「ドコ」を抽出する。
ついでにズンドコを標準出力に出しておく。
Zundoko生成ツール
次に、Groqを使ってズンドコを生成して返すカスタムツールを作る。
カスタムツールの一番簡単な実装は、LangChainのtoolデコレータを付けた関数を定義するだけ。 このデコレータが、単なる関数をLangChainのツールにしてくれて、関数名からツール名を設定し、関数のdocstringからツールのdescriptionを設定してくれる。
GroqのLLMの呼び出しには、LangChainのチャットモデルAPIのChatGroqが使える。
これに前節で作ったZundokoアウトプットパーサをつなげてchainを作り、プロンプトを与えてinvokeすればズンドコを生成できる。
Zundokoアウトプットパーサは単なる関数なんだけど、LCELでつなぐと自動でRunnableLambdaでラップされるので、chainのなかでRunnableとして機能できる。
app/tools/zundoko.py:
from langchain_core.tools import tool
from langchain_groq import ChatGroq
from output_parsers.zundoko_parser import parse_zundoko
_llm = ChatGroq(
model="llama3-8b-8192",
temperature=0,
)
_chain = _llm | parse_zundoko
@tool
def zundoko() -> str:
"""ズンかドコを取得する。"""
return _chain.invoke([
("system", "ズンかドコだけで回答してください。"),
("human", "ズンかドコのどちらかをランダムに返してください。"),
])グラフ定義
次はLangGraphでグラフを定義する。 最初のほうにも貼ったけど、定義したいのは以下のようなグラフ。
LangGraphでグラフ全体を表すクラスはStateGraph。 これにStateのスキーマを渡してインスタンス化することからLangGraphのグラフ定義は始まる。
グラフのStateには、LangGraphに組み込みのMessagesStateを使って、LLMの入出力のメッセージのリストを履歴として保管するようにする。
MessagesStateは具体的には、{ messages: list[Union[AIMessage, HumanMessage, ...]] }というような型の、messagesというキーだけ持ったdict。
(実はMessagesStateを使うなら、StateGraphの代わりにMessageGraphを使うとちょっとだけ楽だけど、StateGraphのほうが汎用的なので今回はこちらを使う。)
agent Nodeでは、OpenAIのFunction calling機能を呼び出して、プロンプトとメッセージ履歴をもとに、実行するツールとツールの引数を決める処理をする。 OpenAI(など)のFunction callingは、LangChainのTool calling機能で簡単に呼び出すことができる。
Tool calling機能は、LangChainのチャットモデルAPI(OpenAIの場合はChatOpenAI)に実装されているbind_tools()に使いたいツールを渡すだけで使える。
bind_tools()したLLMをinvokeすると、どのツールを呼ぶべきかを表すToolCallオブジェクトを含むメッセージ返してくれるので、それをagent Nodeから出力してStateを更新する。
agent NodeからのびるEdgeでは、agent Nodeの最新の出力メッセージにToolCallが含まれていれば、ツールを実行する必要があると判定してtools Nodeに遷移し、含まれてなければ最終回答を得たと判定してEND Nodeに遷移する。 このような条件分岐するEdgeは、StateGraph.add_conditional_edges()に、遷移先のNode名を返す関数を渡してやれば定義できる。
tools Nodeでは、Stateの最新メッセージからToolCallを取得して、それに従って実際にツールを実行し、その結果をメッセージとして返し、Stateを更新する。 ToolCallをもとにツールを実行するNodeは、LangGraphに組み込みのToolNodeクラスで使いたいツールをラップするだけで定義できる。 今回使うツールは、前節で実装したZundoko生成ツールだけ。
tools Nodeからagent Nodeへ無条件に遷移するEdgeは、StateGraph.add_edge()に遷移前後のNodeの名前を渡すことで定義できる。
START NodeとEND Nodeは自分で定義したりグラフに追加する必要はなく、それらに出入りするEdgeだけ定義してやればいい。
START Nodeから最初に実行するNode (i.e. agent Node)へのEdgeの定義は、上記StateGraph.add_edge()でもできるけど、StateGraph.set_entry_point()というシンタックスシュガーが用意されているので、こちらを使う。StateGraph.set_entry_point()には遷移先のNode名を渡すだけでいい。
以上を踏まえた実際の実装が以下。
app/main.py:
from langchain_core.runnables import RunnableLambda
from langchain_openai import ChatOpenAI
from langgraph.graph import END, MessagesState, StateGraph
from langgraph.prebuilt import ToolNode
from tools.zundoko import zundoko
tools = [zundoko]
tool_node = ToolNode(tools)
llm = ChatOpenAI(model="gpt-4o-mini").bind_tools(tools)
agent_node = RunnableLambda(
lambda state: {"messages": [llm.invoke(state["messages"])]}
)
graph = StateGraph(MessagesState)
graph.add_node("agent", agent_node)
graph.add_node("tools", tool_node)
graph.set_entry_point("agent")
graph.add_conditional_edges(
"agent",
lambda state: "tools" if state["messages"][-1].tool_calls else END,
)
graph.add_edge("tools", "agent")
zundoko_agent = graph.compile()
final_state = zundoko_agent.invoke({
"messages": ["ズンかドコを5つ取得して"]
})
print(final_state["messages"][-1].content)グラフを定義した後StateGraph.compile()してるけど、これはグラフ構造のバリデーションとかをして、Runnableに変換してくれるメソッド。
compile()時にCheckpointerとかBreakpointとかを設定できるみたいだけど、今回はやらない。
compile()してできたZundokoエージェントには、とりあえず試しに「ズンかドコを5つ取得して」というプロンプトを与えた。
まずはこれで実行してみる。
$ export OPENAI_API_KEY=sk-proj-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
$ export GROQ_API_KEY=gsk_yyyyyyyyyyyyyyyyyyyyyy
$ python app/main.py
ズン
ズン
ズン
ズン
ズン
取得したズンかドコは以下の通りです:
1. ズン
2. ズン
3. ズン
4. ズン
5. ズン
全て「ズン」でした!すべてズンか…
tools Node改善
Zundoko生成ツールにはズンかドコをランダムに生成してほしかったんだけど、うまく動かなかった。 Zundoko生成ツールには、ぱっと見て以下の2つの問題があるように見える。
- ChatGroqのtemperatureに
0を指定しているが、これは最低値で、LLMの創造性・ランダム性が最小になっている。 - プロンプトが単純すぎ。
一つ目の問題に対しては、temperatureを最大の1に設定してやることで改善できるはず。
二つ目の問題に対しては、ズンドコ生成履歴をプロンプトに与えることで、履歴をもとにズンドコの割合を忖度してもらうようにする。 ついでに、キヨシしやすいようにズンを多めにしてもらうことにする。
app/tools/zundoko.pyの差分:
_llm = ChatGroq(
model="llama3-8b-8192",
- temperature=0,
+ temperature=1,
)
_chain = _llm | parse_zundoko
+zundoko_history = []
+
@tool
def zundoko() -> str:
"""ズンかドコを取得する。"""
- return _chain.invoke([
+ response = _chain.invoke([
("system", "ズンかドコだけで回答してください。"),
- ("human", "ズンかドコのどちらかをランダムに返してください。"),
+ ("human", "ズンかドコのどちらかをランダムに返してください。以前の結果をもとに、ややズン多めでお願いします。"),
+ ("human", f"以前の結果: {zundoko_history}"),
])
+ zundoko_history.append(response)
+ return response
ただし、このズンドコ生成履歴の仕組みは、ズンドコ生成ツールがシーケンシャルに呼ばれることを前提にしていて、そこにまた課題がある。
agent Nodeが「ズンかドコを5つ取得して」というプロンプトに対して、ズンドコ生成ツールに対するToolCallを5個一度に生成することがあって、その場合、ToolNodeは全ToolCallを並列に処理してしまう。 ToolNodeのこの挙動を変える設定は今のところない。
ToolNodeでツールをシーケンシャルに実行させる
LangChainのツールはRunnableなんだけど、RunnableにはRunnableConfigという設定があって、Runnable.with_config()で設定値を指定することで挙動を変えることができる。
この設定の一つにmax_concurrencyというのがあって、1に設定すればRunnableの並列実行を防げる。
これをズンドコ生成ツールに設定してみる。
app/tools/zundoko.pyの差分:
-@tool
def zundoko() -> str:
"""ズンかドコを取得する。"""
response = _chain.invoke([
("system", "ズンかドコだけで回答してください。"),
("human", "ズンかドコのどちらかをランダムに返してください。以前の結果をもとに、ややズン多めでお願いします。"),
("human", f"以前の結果: {zundoko_history}"),
])
zundoko_history.append(response)
return response
+zundoko = tool(zundoko).with_config({"max_concurrency": 1})
結論から言えば、この修正はだめだった。実行時に以下のエラーになる。 理由はよくわからないけど、とにかくtoolデコレータはRunnableConfigを渡せるようになってないっぽい。
$ python app/main.py
Traceback (most recent call last):
File "/root/zundoko-agent/app/main.py", line 8, in <module>
tool_node = ToolNode(tools).with_config({"max_concurrency": 1})
^^^^^^^^^^^^^^^
File "/root/zundoko-agent/zundoko-agent/lib/python3.12/site-packages/langgraph/prebuilt/tool_node.py", line 81, in __init__
tool_ = create_tool(tool_)
^^^^^^^^^^^^^^^^^^
File "/root/zundoko-agent/zundoko-agent/lib/python3.12/site-packages/langchain_core/tools/convert.py", line 224, in tool
raise ValueError("Too many arguments for tool decorator")
ValueError: Too many arguments for tool decorator別のアプローチを探る。
ToolNodeのソースをみると、複数のToolCallを処理するとき、RunnableConfigのmax_concurrencyの値をmax_workersにセットしたContextThreadPoolExecutorをつくり、それで並列実行していた。
そのRunnableConfigがどこからくるかというと、ToolNode自体のRunnableConfigが渡ってきているようだったので、ToolNodeにmax_concurrencyを設定してやってもよさそう。
あまりきれいじゃないけど、今回はToolNodeで実行するのがズンドコ生成ツールだけなので特に問題ない。
(convert_runnable_to_toolというのがあったのでこれを使ったらもっときれいだったかも。)
app/main.pyの差分:
tools = [zundoko]
-tool_node = ToolNode(tools)
+tool_node = ToolNode(tools).with_config({"max_concurrency": 1})
llm = ChatOpenAI(model="gpt-4o-mini").bind_tools(tools)
これで実行してみる。
$ python app/main.py
ズン
ドコ
ズン
ズン
ズン
取得したズンかドコは以下の通りです:
1. ズン
2. ドコ
3. ズン
4. ズン
5. ズン
ご覧のように、ズンが多く取得されました。ちょっとズンが多すぎな気がするがまあよし。
Zundokoエージェント完成
最後にプロンプトをズンドコキヨシにする。
zundoko_agent = graph.compile()
-final_state = zundoko_agent.invoke({
- "messages": ["ズンかドコを5つ取得して"]
-})
+msg = """
+以下を実行してください。
+1. ズンかドコを一つだけ取得する。
+2. 直近で取得した5つのズンとドコを、取得した順に並べる
+3. その結果を確認し、はじめに4つのズンが連続し、最後がドコになっていたら「キ・ヨ・シ!」を出力した後終了する。そうでなければ最初の手順に戻る。
+"""
+final_state = zundoko_agent.invoke({"messages": msg}, {"recursion_limit": 50})
print(final_state["messages"][-1].content)
プロンプトは、冒頭のツイートの内容を与えてもあまりうまく動いてくれなかったので、ステップを刻んでやってほしいことを正確に伝えるようにした。
また、ズンドコエージェントをinvoke()するときに、RunnableConfigのrecursion_limitをデフォルトの25より多めに設定して、キヨシ判定に至るまでズンドコできる猶予を増やした。
ちなみにキヨシ判定が遅れてNodeの実行回数がrecursion_limitに至ると、以下のエラーになってしまう。
langgraph.errors.GraphRecursionError: Recursion limit of 25 reached without hitting a stop condition. You can increase the limit by setting the `recursion_limit` config key.これで実行してみる。
$ python app/main.py
ドコ
ズン
ズン
ドコ
ズン
ズン
ズン
ズン
ズン
ズン
ズン
ドコ
取得したズンとドコの順番は以下の通りです:
1. ズン
2. ズン
3. ズン
4. ズン
5. ドコ
最初の4つがズンで、最後がドコですので、「キ・ヨ・シ!」を出力します。なんかぎこちないけど一応ズンドコキヨシできた。
実際のところ、何度か試した結果、結構キヨシ判定を間違うことが多かったので、GPT-4o miniはズンドコキヨシに向いてなさそうという知見を得た。